python提取网页文章html正文的API和开源算法
0
开源项目:
1.arex
https://github.com/ahkimkoo/arex
2.html2Article
http://www.cnblogs.com/jasondan/p/3497757.html
主要python包:
requests;
xml;
jparser;
url2io。
其中jparser、url2io都用于网页文本正文提取,url2io准确率高,但不稳定,解析错误时则调用jparser。通过两者结合使用来提高正文提取的效果。
jparser
安装:
pip install jparser
使用:
参考官网:https://pypi.org/project/jparser/0.0.10/
url2io
下载安装,即下载url2io.py文件。
可以到这个github项目上下载:https://github.com/Neo-Luo/scrapy_baidu
github主页下载最新版:https://github.com/url2io/url2io-python-sdk/
官网注册
获取token:http://url2io.applinzi.com/
使用:https://github.com/url2io/url2io-python-sdk/
url2io python3
#coding: utf-8 # # This program is free software. It comes without any warranty, to # the extent permitted by applicable law. You can redistribute it # and/or modify it under the terms of the Do What The Fuck You Want # To Public License, Version 2, as published by Sam Hocevar. See # http://sam.zoy.org/wtfpl/COPYING (copied as below) for more details. # # DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE # Version 2, December 2004 # # Copyright (C) 2004 Sam Hocevar <sam@hocevar.net> # # Everyone is permitted to copy and distribute verbatim or modified # copies of this license document, and changing it is allowed as long # as the name is changed. # # DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE # TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION # # 0. You just DO WHAT THE FUCK YOU WANT TO. """a simple url2io sdk example: api = API(token) api.article(url='http://www.url2io.com/products', fields=['next', 'text']) """ __all__ = ['APIerror', 'API'] DEBUG_LEVEL = 1 import sys import socket import json import urllib,urllib.request,urllib.error,urllib.parse from urllib.request import urlopen import time from collections import Iterable class APIError(Exception): code = None """HTTP status code""" url = None """request URL""" body = None """server response body; or detailed error information""" def __init__(self, code, url, body): self.code = code self.url = url self.body = body def __str__(self): return 'code={s.code}\nurl={s.url}\n{s.body}'.format(s = self) __repr__ = __str__ class API(object): token = None server = 'http://api.url2io.com/' decode_result = True timeout = None max_retries = None retry_delay = None def __init__(self, token, srv = None, decode_result = True, timeout = 30, max_retries = 5, retry_delay = 3): """:param srv: The API server address :param decode_result: whether to json_decode the result :param timeout: HTTP request timeout in seconds :param max_retries: maximal number of retries after catching URL error or socket error :param retry_delay: time to sleep before retrying""" self.token = token if srv: self.server = srv self.decode_result = decode_result assert timeout >= 0 or timeout is None assert max_retries >= 0 self.timeout = timeout self.max_retries = max_retries self.retry_delay = retry_delay _setup_apiobj(self, self, []) def update_request(self, request): """overwrite this function to update the request before sending it to server""" pass def _setup_apiobj(self, apiobj, path): if self is not apiobj: self._api = apiobj self._urlbase = apiobj.server + '/'.join(path) lvl = len(path) done = set() for i in _APIS: if len(i) <= lvl: continue cur = i[lvl] if i[:lvl] == path and cur not in done: done.add(cur) setattr(self, cur, _APIProxy(apiobj, i[:lvl + 1])) class _APIProxy(object): _api = None _urlbase = None def __init__(self, apiobj, path): _setup_apiobj(self, apiobj, path) def __call__(self, post = False, *args, **kwargs): # /article # url = 'http://xxxx.xxx', # fields = ['next',], # if len(args): raise TypeError('only keyword arguments are allowed') if type(post) is not bool: raise TypeError('post argument can only be True or False') url = self.geturl(**kwargs) request = urllib.request.Request(url) self._api.update_request(request) retry = self._api.max_retries while True: retry -= 1 try: ret = urlopen(request, timeout = self._api.timeout).read() break except urllib.error.HTTPError as e: raise APIError(e.code, url, e.read()) except (socket.error, urllib.error.URLError) as e: if retry < 0: raise e _print_debug('caught error: {}; retrying'.format(e)) time.sleep(self._api.retry_delay) if self._api.decode_result: try: ret = json.loads(ret) except: raise APIError(-1, url, 'json decode error, value={0!r}'.format(ret)) return ret def _mkarg(self, kargs): """change the argument list (encode value, add api key/secret) :return: the new argument list""" def enc(x): #if isinstance(x, unicode): # return x.encode('utf-8') #return str(x) return x.encode('utf-8') if isinstance(x, str) else str(x) kargs = kargs.copy() kargs['token'] = self._api.token for (k, v) in kargs.items(): if isinstance(v, Iterable) and not isinstance(v, str): # kargs[k] = ','.join([enc(i) for i in v]) kargs[k] = ','.join([str(i) for i in v]) else: kargs[k] = enc(v) return kargs def geturl(self, **kargs): """return the request url""" return self._urlbase + '?' + urllib.parse.urlencode(self._mkarg(kargs)) def _print_debug(msg): if DEBUG_LEVEL: sys.stderr.write(str(msg) + '\n') _APIS = [ '/article', #'/images', ] _APIS = [i.split('/')[1:] for i in _APIS]
主要代码:
# -*- coding:utf-8 -*-
import url2io,requests,time
from jparser import PageModel
from newspaper import Article
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) chrome/63.0.3239.132 Safari/537.36',
}
def get_url2io(url):
try:
ret = api.article(url=url, fields=['text', 'next'])
content=ret['text'].replace('\r', '').replace('\n', '')
return content
except Exception as e:
# import traceback
# ex_msg = '{exception}'.format(exception=traceback.format_exc())
# print(ex_msg, e)
return ''
def get_jparser(url):
try:
response = requests.get(url, headers=headers)
en_code = response.encoding
de_code = response.apparent_encoding
# print(en_code,de_code,'-----------------')
if de_code == None:
if en_code in ['utf-8', 'UTF-8']: # en_code=utf-8时,de_code=utf-8,可以获取到内容
de_code = 'utf-8'
elif de_code in ['ISO-8859-1', 'ISO-8859-2', 'Windows-1254', 'UTF-8-SIG']:
de_code = 'utf-8'
html = response.text.encode(en_code, errors='ignore').decode(de_code, errors='ignore')
pm = PageModel(html)
result = pm.extract()
ans = [x['data'] for x in result['content'] if x['type'] == 'text']
content=''.join(ans)
return content
except Exception as e:
# import traceback
# ex_msg = '{exception}'.format(exception=traceback.format_exc())
# print(ex_msg, e)
return ''
if __name__=='__main__':
token = '111111111' # 请到url2io官网注册获取token
api = url2io.API(token)
url = 'https://36kr.com/p/5245238'
url = 'http://sc.stock.cnfol.com/ggzixun/20190909/27678429.shtml'
url='https://news.pedaily.cn/201908/445881.shtml'
# content=get_url2io(url)
content = get_jparser(url)
print(content)
Python Goose的使用:
代码比较方便,但是有些网址没有解析出来。
示例代码如下所示:
from goose import Goose
from goose.text import StopWordsChinese
url = 'http://www.chinanews.com/gj/2014/11-19/6791729.shtml'
g = Goose({'stipwords_class':StopWordsChinese})
article = g.extract(url = url)
print article.cleaned_text[:150]
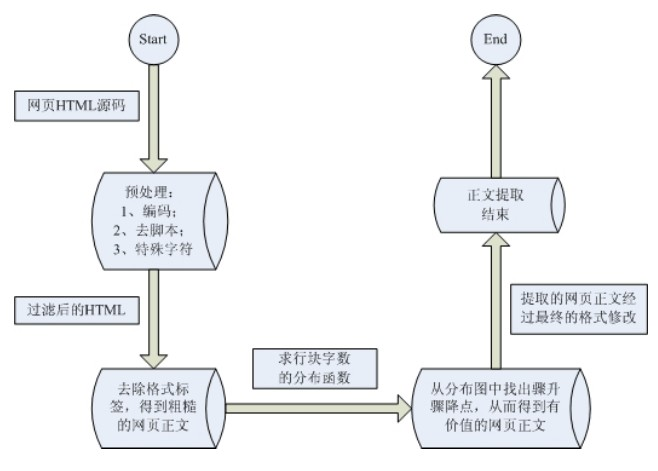
基于行块分布函数的通用网页正文抽取
http://wenku.baidu.com/link?url=TOBoIHWT_k68h5z8k_Pmqr-wJMPfCy2q64yzS8hxsgTg4lMNH84YVfOCWUfvfORTlccMWe5Bd1BNVf9dqIgh75t4VQ728fY2Rte3x3CQhaS
网页正文及内容图片提取算法
http://www.jianshu.com/p/d43422081e4b
这一算法的主要原理基于两点:
正文区密度:在去除HTML中所有tag之后,正文区字符密度更高,较少出现多行空白;
行块长度:非正文区域的内容一般单独标签(行块)中较短。
测试源码:
https://github.com/rainyear/cix-extractor-py/blob/master/extractor.py#L9
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import requests as req
import re
DBUG = 0
reBODY = r'<body.*?>([\s\S]*?)<\/body>'
reCOMM = r'<!--.*?-->'
reTRIM = r'<{0}.*?>([\s\S]*?)<\/{0}>'
reTAG = r'<[\s\S]*?>|[ \t\r\f\v]'
reIMG = re.compile(r'<img[\s\S]*?src=[\'|"]([\s\S]*?)[\'|"][\s\S]*?>')
class Extractor():
def __init__(self, url = "", blockSize=3, timeout=5, image=False):
self.url = url
self.blockSize = blockSize
self.timeout = timeout
self.saveImage = image
self.rawPage = ""
self.ctexts = []
self.cblocks = []
def getRawPage(self):
try:
resp = req.get(self.url, timeout=self.timeout)
except Exception as e:
raise e
if DBUG: print(resp.encoding)
resp.encoding = "UTF-8"
return resp.status_code, resp.text
#去除所有tag,包括样式、Js脚本内容等,但保留原有的换行符\n:
def processTags(self):
self.body = re.sub(reCOMM, "", self.body)
self.body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", self.body))
# self.body = re.sub(r"[\n]+","\n", re.sub(reTAG, "", self.body))
self.body = re.sub(reTAG, "", self.body)
#将网页内容按行分割,定义行块 blocki 为第 [i,i+blockSize] 行文本之和并给出行块长度基于行号的分布函数:
def processBlocks(self):
self.ctexts = self.body.split("\n")
self.textLens = [len(text) for text in self.ctexts]
self.cblocks = [0]*(len(self.ctexts) - self.blockSize - 1)
lines = len(self.ctexts)
for i in range(self.blockSize):
self.cblocks = list(map(lambda x,y: x+y, self.textLens[i : lines-1-self.blockSize+i], self.cblocks))
maxTextLen = max(self.cblocks)
if DBUG: print(maxTextLen)
self.start = self.end = self.cblocks.index(maxTextLen)
while self.start > 0 and self.cblocks[self.start] > min(self.textLens):
self.start -= 1
while self.end < lines - self.blockSize and self.cblocks[self.end] > min(self.textLens):
self.end += 1
return "".join(self.ctexts[self.start:self.end])
#如果需要提取正文区域出现的图片,只需要在第一步去除tag时保留<img>标签的内容:
def processImages(self):
self.body = reIMG.sub(r'{{\1}}', self.body)
#正文出现在最长的行块,截取两边至行块长度为 0 的范围:
def getContext(self):
code, self.rawPage = self.getRawPage()
self.body = re.findall(reBODY, self.rawPage)[0]
if DBUG: print(code, self.rawPage)
if self.saveImage:
self.processImages()
self.processTags()
return self.processBlocks()
# print(len(self.body.strip("\n")))
if __name__ == '__main__':
ext = Extractor(url="http://blog.rainy.im/2015/09/02/web-content-and-main-image-extractor/",blockSize=5, image=False)
print(ext.getContext())
参考资料:
 微信 支付宝 QQ 扫码打赏
微信 支付宝 QQ 扫码打赏
html python爬取网页内容 html论文 java解析html java获取html标签中的内容 python嵌入到html5 python提取html文件中的内容 python获取网页源码 python编辑html里的表 python与html结合 python读取html文件